线上的应用运行几天后,总是出现卡死甚至出现OOM的情况
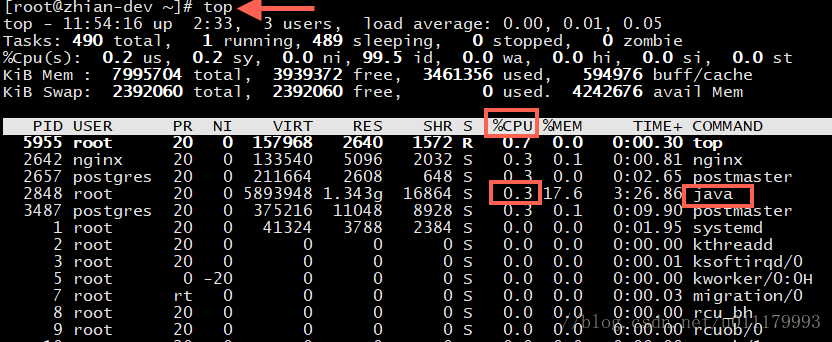
通过Linux的top命令查看cpu占比
首先通过top命令查看,发现某个java程序占用了较高内存:
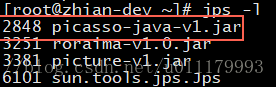
JDK的jps命令确定是哪个java程序
然后通过jps -l 与上面的PID列(2848)比较,确定是 picasso-java-v1.jar 这个java程序占用cpu过高:
通过ps 查看具体哪个JVM线程
当时想的是可能应用内某个线程导致死循环,使用如下命令查看2848进程的各个线程小号cpu时间
//ps -mp [线程号] -o THREAD,tid,time
ps -mp 2848 -o THREAD,tid,time
下图 %CPU列 为 cpu的百分比,TID列 为线程id
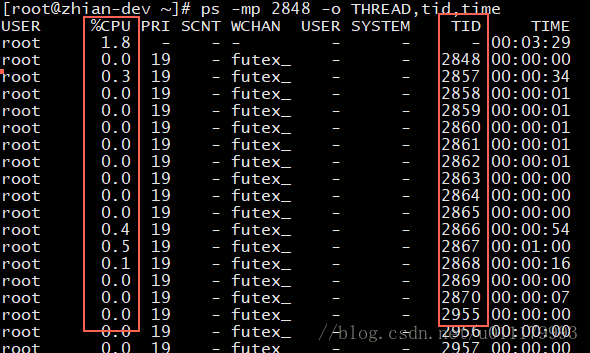
找到消耗cpu最大的线程(当时线上出现时某个线程消耗cpu90%多),这里为了演示,所以取2858这个线程。
通过jstack查看java中的具体线程栈信息
然后把上面线程id转化为16进制,在shell中使用printf “%x\n” tid即可,结果为b2a:

然后使用jstack输出这个线程的调用栈:
//jstack [进程id] | grep [线程的16进制id] -A行数
jstack 2848 | grep b2a -A30
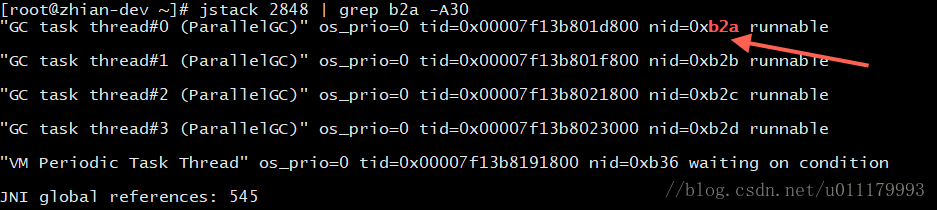
发现为GC线程,原来是jvm内存回收导致的cpu过高!
通过jstat查看内存回收情况
使用jstat -gcutil 线程数 间隔秒数 次数命令查看:

如图上面的FGC列Full GC次数为几百,而FGCT的Full GC秒数达到了几千,通过设置更多的监控次数观察,每次Full GC过后,O列的老年代还是99%,可见是内存不足导致的一直不停Full GC !
重启程序,使用-Xmx -Xms设置更大堆内存
通过重启程序, -Xmx2048m -Xms2048m 设置了更大的内存参数,缓解了问题!
问题重现,寻找其他原因,使用jmap生成堆转储文件
隔了几天后,问题重现,此时通过jmap 生成了镜像
jmap -dump:format=b,file=dumpfile.dat [pid]
生成的文件也是非常之大,达到2.1Gb!
柳暗花明,使用Eclipse Memory Analyzer分析出原因
把dump文件下载到本地,同时下载了Eclipse Memory Analyzer对dump文件进行分析。
在Eclipse Memory Analyzer中生成Leak Suspects报告:
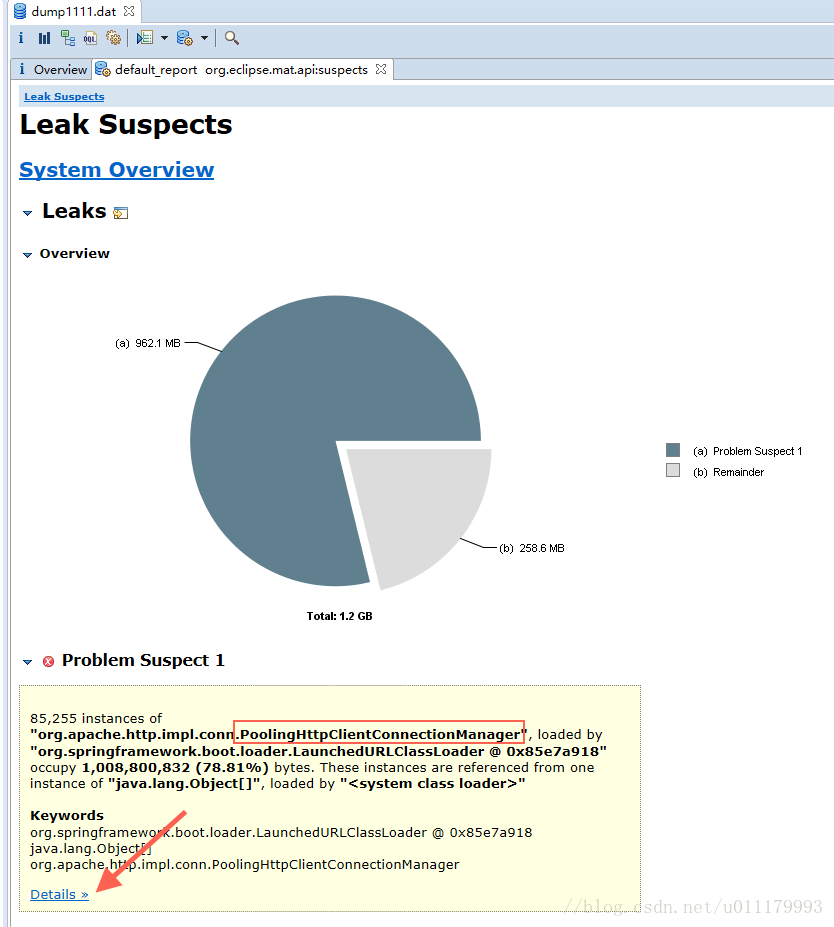
发现是 PoolingHttpClientConnectionManager 这个类导致的。再点击上图中的Details,查看详细信息:
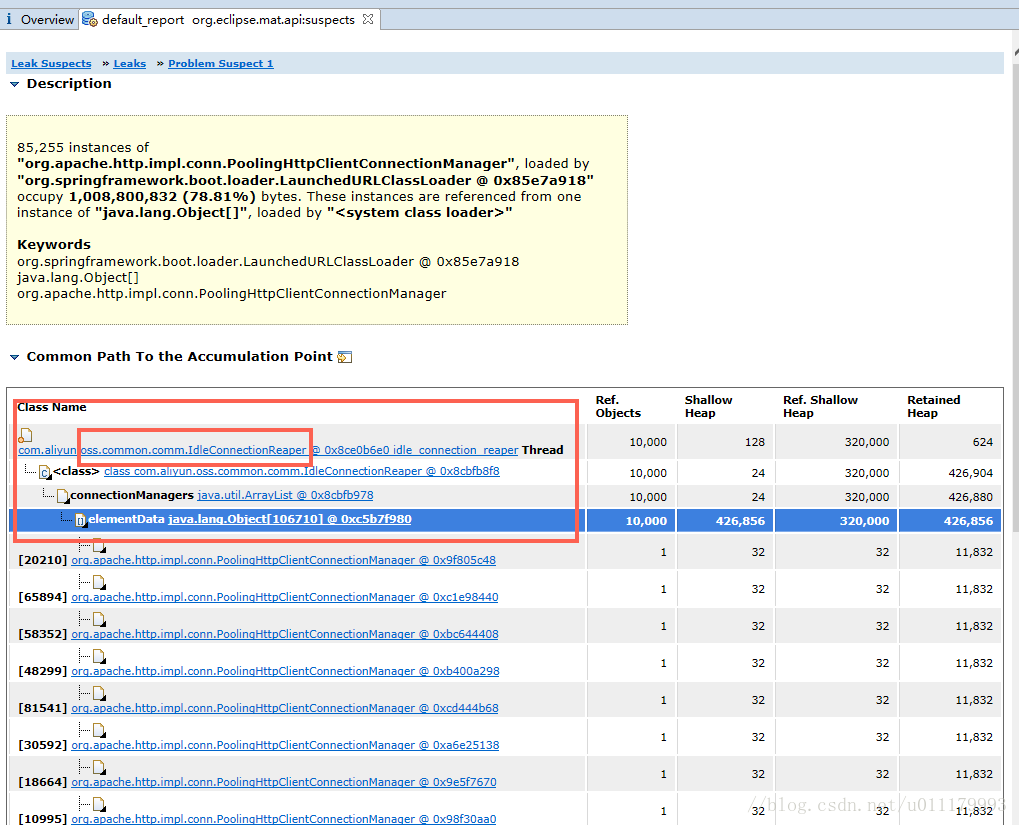
这下清晰了,是阿里的oss类库导致的,结合程序中的如下代码:
1 | OSSClient ossClient = new OSSClient("",""); |
这个方法在程序中没有使用单例模式而且没有关闭,每调用一次就生成了一个PoolingHttpClientConnectionManager,而且是不可回收的。通过源码查看到IdleConnectionReaper.size()这个类会生成PoolingHttpClientConnectionManager的总数量。
验证猜测
使用 -Xms20m -Xmx20m 运行以下程序,发现size一直变大,最后导致OOM (java.lang.OutOfMemoryError)
1 |
|
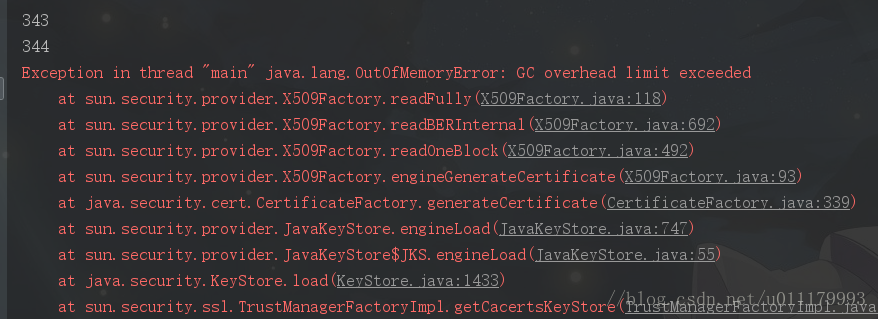
查看api,得知使用shutdown方法即可关闭OSSClient:
1 | ossClient.shutdown(); |
再运行以下程序,size一直为0,一切正常:
1 | for (int i = 0; i < 60000; i++) { |
至此,终于找到了导致cpu过高和OutOfMemoryError的真凶!
原文链接:

