HashMap作为Java集合类重要的元素之一,其蕴含的精妙代码设计,除了在工作中经常用到之外,也是面试中常见的考点。普通的程序员,可能仅仅能说出HashMap线程不安全,允许key、value为null,以及不要求线程安全时,效率上比HashTable要快一些。稍微好一些的,会对具体实现有过大概了解,能说出HashMap由数组+链表+RBT实现(JDK8),并了解HashMap的扩容机制。如果你有刨根问底的激情,那么你肯定想知道它具体是如何实现的。
本文将从下几个方面进行剖析:HashMap的结构、put方法、get方法、remove方法、resize方法。
以下HashMap源码基于JDK 8
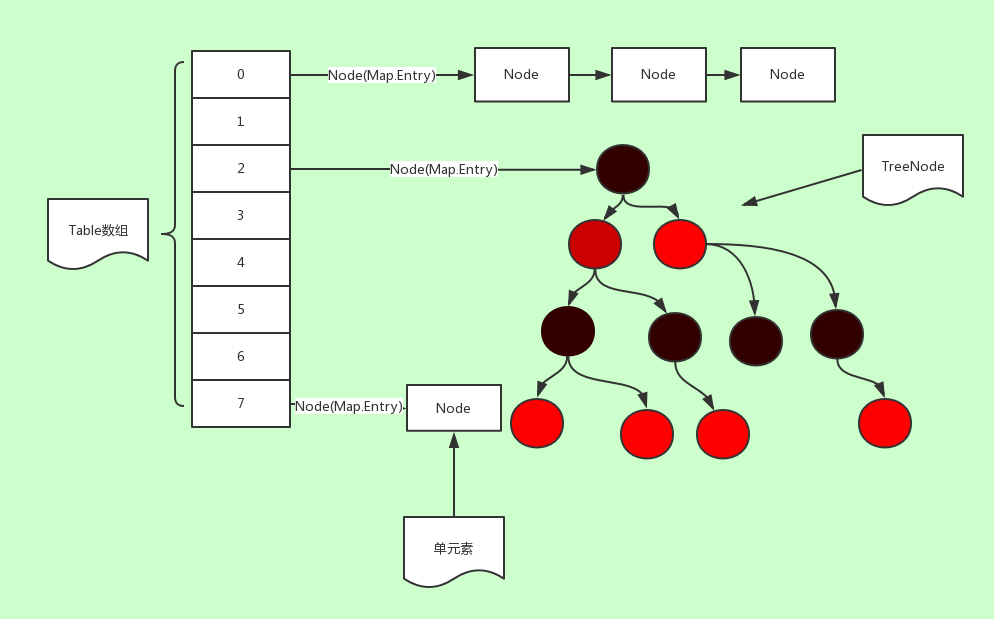
HashMap结构
JDK1.8 以前HashMap的实现是:数组+链表
JDK1.8 开始HashMap的实现是:数组+链表+红黑树
如下图:
强烈推荐一个数据结构可视化的网站:
这里先了解HashMap的几个核心成员变量:
1 |
|
为什么TREEIFY_THRESHOLD的默认值被设定为8?HashMap中有这样一段注释:
1 | * Because TreeNodes are about twice the size of regular nodes, we |
理想情况,在随机哈希码下,容器中的节点遵循泊松分布(Poisson),按照泊松分布的计算公式计算出了链表中元素个数和概率的对照表,可以看到链表中元素个数为8时的概率已经非常小。
另一方面红黑树平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是链表和红黑树之间的转换也很耗时。选择6和8,中间还有个差值7可以有效防止链表和树频繁转换。
再看下另外的几个成员变量:
1 |
|
显然,HashMap的底层实现是基于一个Node的数组,其是HashMap的一个内部类:
1 | static class Node<K,V> implements Map.Entry<K,V> { |
它实现了Map.Entry接口,内部的变量含义也很明确,hash值、key/value对和实现链表和红黑树所需要的指针索引。
HashMap内部定义的几个变量,包括桶数组本身都是transient修饰,这代表了他们无法被序列化,而HashMap本身是实现了Serializable接口的。
这很容易产生疑惑:HashMap是如何序列化的呢?查了源码发现,HashMap内有两个用于序列化的函数 readObject(ObjectInputStream s) 和 writeObject(ObjectOutputStreams),通过这个函数将table序列化。
put方法解析
1 | public V put(K key, V value) { |
在上述代码中的第十行,HashMap根据 (n - 1) & hash 求出了元素在node数组的下标。这个操作非常精妙,下面我们仔细分析一下计算下标的过程,主要分三个阶段:计算hashcode、高位运算和取模运算。
首先,传进来的hash值是由put方法中的hash(key)产生的(上述第2行),我们来看一下hash()方法的源码:
1 | static final int hash(Object key) { |
这里通过key.hashCode()计算出key的哈希值,然后将哈希值h右移16位,再与原来的h做异或^运算——这一步是高位运算。设想一下,如果没有高位运算,那么hash值将是一个int型的32位数。而从2的-31次幂到2的31次幂之间,有将近几十亿的空间,如果我们的HashMap的table有这么长,内存早就爆了。所以这个散列值不能直接用来最终的取模运算,而需要先加入高位运算,将高16位和低16位的信息”融合”到一起,也称为”扰动函数”。这样才能保证hash值所有位的数值特征都保存下来而没有遗漏,从而使映射结果尽可能的松散。最后,根据 n-1 做与操作的取模运算。
这里也能看出为什么HashMap要限制table的长度为2的n次幂,因为这样,n-1可以保证二进制展示形式是(以n=16为例)0000 0000 0000 0000 0000 0000 0000 1111。在做”与”操作时,就等同于截取hash二进制值得后四位数据作为下标。这里也可以看出”扰动函数”的重要性了,如果高位不参与运算,那么高16位的hash特征几乎永远得不到展现,发生hash碰撞的几率就会增大,从而影响性能。
HashMap的put方法的源码实现就是这样了,整理思路非常连贯。这里面有几个函数的源码(比如resize、putTreeValue、newNode、treeifyBin)限于篇幅原因,就不贴了,有兴趣的同学也可以自己挖掘一下。
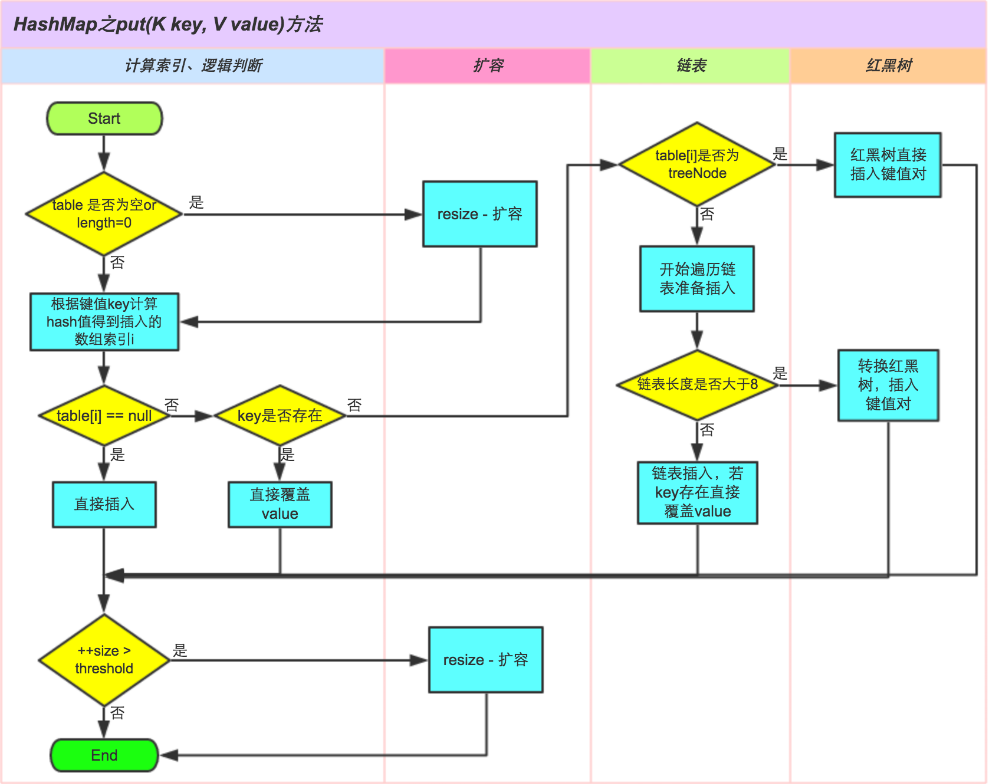
附上put方法简易流程图,辅助理解:
get方法解析
读完了put的源码,其实已经可以很清晰的理清HashMap的工作原理了。接下来再看get方法的源码,就非常的简单:
1 | public V get(Object key) { |
因为查询过程不涉及到HashMap的结构变动,所以get方法的源码显得很简洁。核心逻辑就是遍历table某特定位置上的所有节点,分别与key进行比较看是否相等。
remove方法解析
1 | public V remove(Object key) { |
resize方法解析
扩容时机:
- 当为空的时候,也就是没有初始化的时候
- 当到达最大值时候
- 普通扩容时候
1 | final Node<K,V>[] resize() { |
Java8在扩容后重新计算位置的时候,对链表进行优化,有兴趣可以搜索一下HashMap导致cpu百分之百的问题。而在Java中通过巧妙的进行&操作,然后获得高位是为0还是1,最终移动的位置就是低位的链表留在原地,高位的放在index+oldsize的地方就可以了。不用为每一个元素计算hash值,然后移动到对应的位置,再判断是否是链表,是否需要转换成树的操作。
JDK 7以前的HashMap相关实现原理,和JDK 8以后还是有点区别的,可参考:
写在最后
问:HashMap如果确定只装载100个元素,new HashMap(?)多少是最佳的,为什么?
HashMap有两个参数影响其性能:初始容量和加载因子,前文我们已经分析了相关的代码。当哈希表中条目的数目超过容量乘加载因子的时候,则要对该哈希表进行resize扩容操作,从而哈希表将具有大约两倍的桶数。HashMap默认的加载因子是0.75,它在时间和空间成本上寻求了一种折中。
回到本文的问题。如果这个只装载100个元素的HashMap没有特殊的用途,那么为了在时间和空间上达到最佳性能,HashMap的初始容量可以设为:
100/0.75 = 133.33,为了防止resize,向上取整,为134。
但是还有另外一个问题,就是hash碰撞的问题。如果我们将HashMap的容量设置为134,那么如何保证其中的哈希碰撞会比较少呢?除非重写hashcode()方法,否则,似乎没有办法保证。
Put方法的第10行代码处,也给出了HashMap如何为元素选择下标的方法:p = tab[i = (n - 1) & hash])。hash为key哈希后得到的值,n为哈希表的长度。
134-1 = 128 + 6 -1;
假设这100个装载的元素中他们的key在哈希后有得到两个值(h),他们的二进制值除了低3位之外都相同,而第一个值的低3位为011,第二个值的低3位为001;
这时候进行java的&预算,011 & 101 = 001 ;001 & 101 = 001;他们的值相等了,那么这个时候就会发生哈希碰撞。
除此之外还有一个更加严重的问题,由于在101中第二位是0,那么,无论我们的key在哈希运算之后得到的值h是什么,那么在&运算之后,得到的结果的倒数第二位均为0;
因此,对于hash表所有下标的二进制的值而言,只要低位第二位的值为1,(例如0010,0011,0111,1111)那么这个下标所代表的桶将一直是空的,因为代码中的&运算的结果永远不会产生低位第二位为1的值。这就大大地浪费了空间,同时还增加了哈希碰撞的概率。这无疑会降低HashMap的效率。
那么如何才能减少这种浪费呢?最佳的方法当然是让length-1的二进制值全部位均为1。那么多少合适呢?没错,length=2^n,只要将hash表的长度设为2的N次方,那么,所有的哈希桶均有被使用的可能。
再次验证了HashMap要限制table的长度为2的n次幂的一个原因
回到刚才问题,与134最靠近的2^n无疑是128。但是100/128=0.78,已经超过默认加载因子的大小了。HashMap会进行resize操作,变成256。所以最好的结果还是256。
补充:在Java中,无论你的HashMap(x)中的x设置为多少,HashMap的大小都是2^n。2^n是大于x的第一个数。
参考文章:
深入Java集合学习系列:HashMap的实现原理
Java8 HashMap源码分析
java 8 Hashmap深入解析—put get 方法源码
在元素的装载数量明确的时候HashMap的大小应该如何选择

